外观
MVCC 原理是什么?
⭐ 题目日期:
阿里 - 2024/8/21,腾讯 - 2024/08/19
📝 题解:
MVCC(多版本并发控制)是一种通过维护数据的多个版本来实现高并发访问的技术,确保事务在读取数据时看到一致的快照,避免阻塞写操作。其核心原理如下:
1. 核心机制
- 数据版本链:每行数据维护多个版本,每个版本包含:
- 创建事务ID(trx_id):生成该版本的事务ID。
- 删除事务ID(roll_pointer):指向回滚日志(Undo Log)的指针,用于追溯旧版本。
- 事务ID分配:每个事务启动时分配唯一递增的ID(
trx_id),用于判断数据可见性。
2. 快照读(Snapshot Read)
- Read View:事务在首次读操作时生成一个快照,记录当前活跃事务ID集合。
- 可见性规则:数据版本对事务可见的条件:
- 版本trx_id < 当前事务trx_id,且该事务已提交。
- 版本trx_id不在活跃事务集合中(即已提交)。
3. 版本链遍历
- 访问流程:事务读取数据时,从最新版本开始,沿回滚指针(roll_pointer)回溯,找到满足可见性的最旧版本。
最新版本 → 版本2 → 版本1 → 版本04. 写操作处理
- 更新操作:创建新版本,旧版本通过Undo Log保留。
- 删除操作:标记删除版本,实际清理由Purge线程异步执行。
5. MVCC 解决并发问题
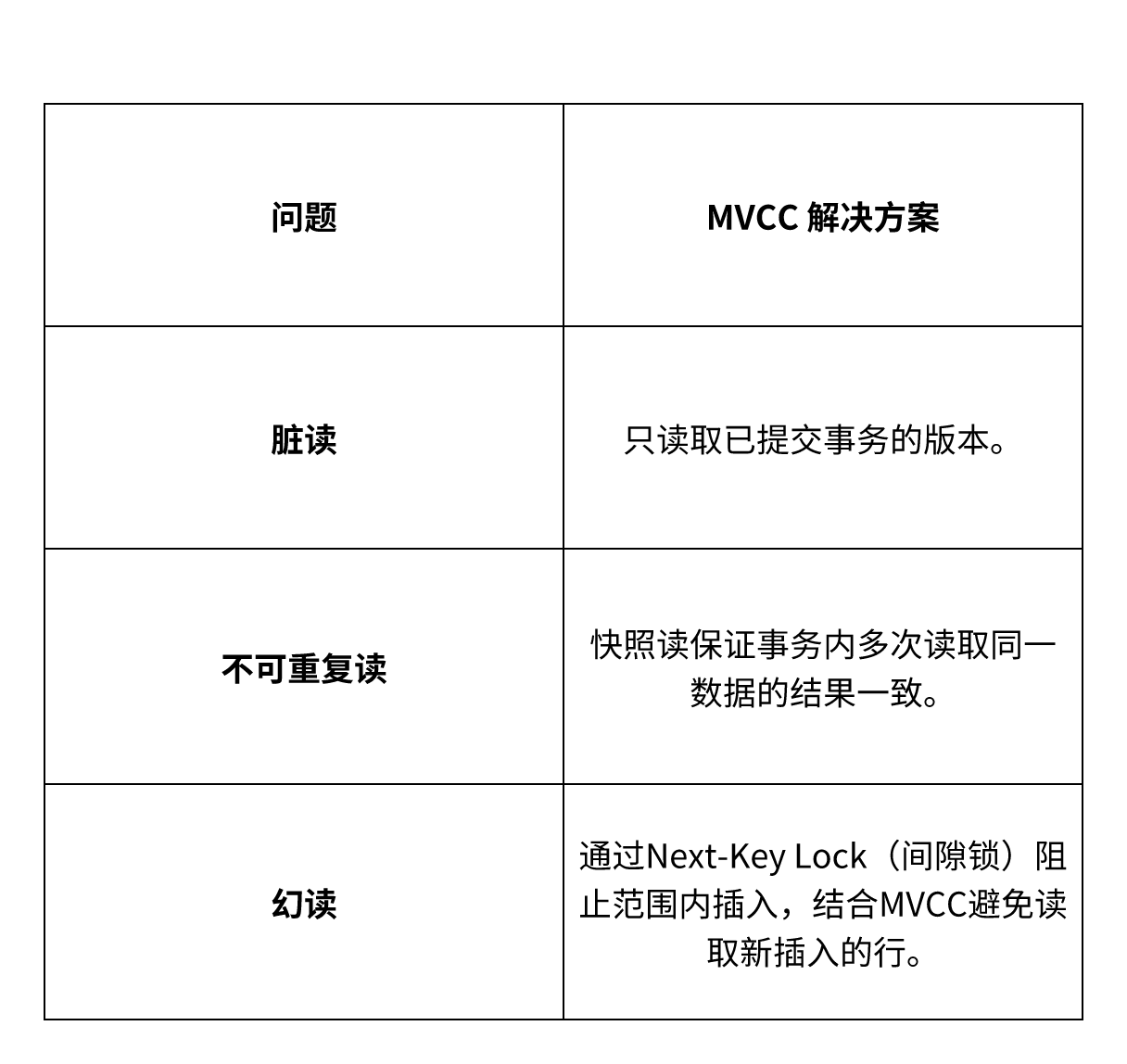
6. 实现差异(InnoDB vs PostgreSQL)

7. 优势与局限
- 优势:
- 读写无锁:读操作不阻塞写,写操作不阻塞读。
- 高并发:减少锁竞争,适合OLTP场景。
- 局限:
- 存储开销:需维护多版本和Undo Log。
- 清理机制:需定期Purge旧版本,可能影响性能。
8. 示例场景
事务A(trx_id=100)读取数据
数据版本链:版本3(trx_id=90,已提交) ← 版本2(trx_id=80,已提交) ← 版本1(trx_id=50,已提交)
Read View活跃事务:{95, 105}
可见版本:版本3(trx_id=90 < 100 且不在活跃集合中)。事务B(trx_id=105)更新同一数据
- 创建新版本4(trx_id=105),事务A仍读取版本3(快照隔离)。
总结
MVCC通过多版本管理、快照读和可见性规则,实现了高效的并发控制,是现代数据库(如MySQL、PostgreSQL)实现高并发的核心技术。