外观
innoDB 的索引结构
⭐ 题目日期:
小米 - 2024/12/26, 字节 - 2024/09/03
📝 题解:
MySQL 的 InnoDB 存储引擎采用 B+树(B+ Tree) 作为其索引结构的核心实现,这种设计结合了高效的查询性能、范围查询支持以及数据有序性管理。以下是 InnoDB 索引结构的详细解析:
1. B+树的核心特点
- 平衡多路搜索树:所有叶子节点位于同一层,保证查询效率稳定(时间复杂度为 O(logN))。
- 非叶子节点仅存键值和指针:不存储实际数据,仅用于路由导航。
- 叶子节点形成有序链表:所有数据按顺序存储在叶子节点,并通过双向链表连接,高效支持范围查询。
- 高扇出(Fan-out):每个节点可存储大量键值,减少树的高度(通常 3-4 层即可存储千万级数据)。
2. InnoDB 的索引类型
(1) 聚集索引(Clustered Index)
- 数据与索引绑定:叶子节点直接存储完整的行数据(即数据页)。
- 物理有序性:数据按主键顺序物理存储,主键查询极快。
- 唯一性:每张表必须有且仅有一个聚集索引:
- 若显式定义主键,则主键为聚集索引。
- 若未定义主键,自动选择第一个非空唯一索引(UNIQUE)作为聚集索引。
- 若无任何唯一索引,隐式生成一个
ROW_ID列作为聚集索引。
(2) 辅助索引(Secondary Index)
- 独立于数据存储:叶子节点存储主键值(而非数据行)。
- 回表(Bookmark Lookup):通过辅助索引查询时,需根据主键值到聚集索引中查找完整数据(可能引发额外 I/O)。
- 覆盖索引****优化:若查询字段全在辅助索引中,无需回表,直接返回数据(效率高)。
3. InnoDB 索引的物理存储
- 页(Page)为单位:InnoDB 默认页大小为 16KB,每个索引(B+树)由多个页构成。
- 页内结构:
- 文件头(File Header):记录页的元信息(如前后页指针)。
- 索引记录(Index Records):按顺序存储键值及指针(非叶子节点)或数据行(叶子节点)。
- 页目录(Page Directory):对页内记录进行二分查找加速(类似跳表)。
- 页分裂与合并:
- 插入数据导致页溢出时:触发页分裂(Split),新页分配并调整树结构。
- 删除数据导致页利用率过低时:可能触发页合并(Merge)。
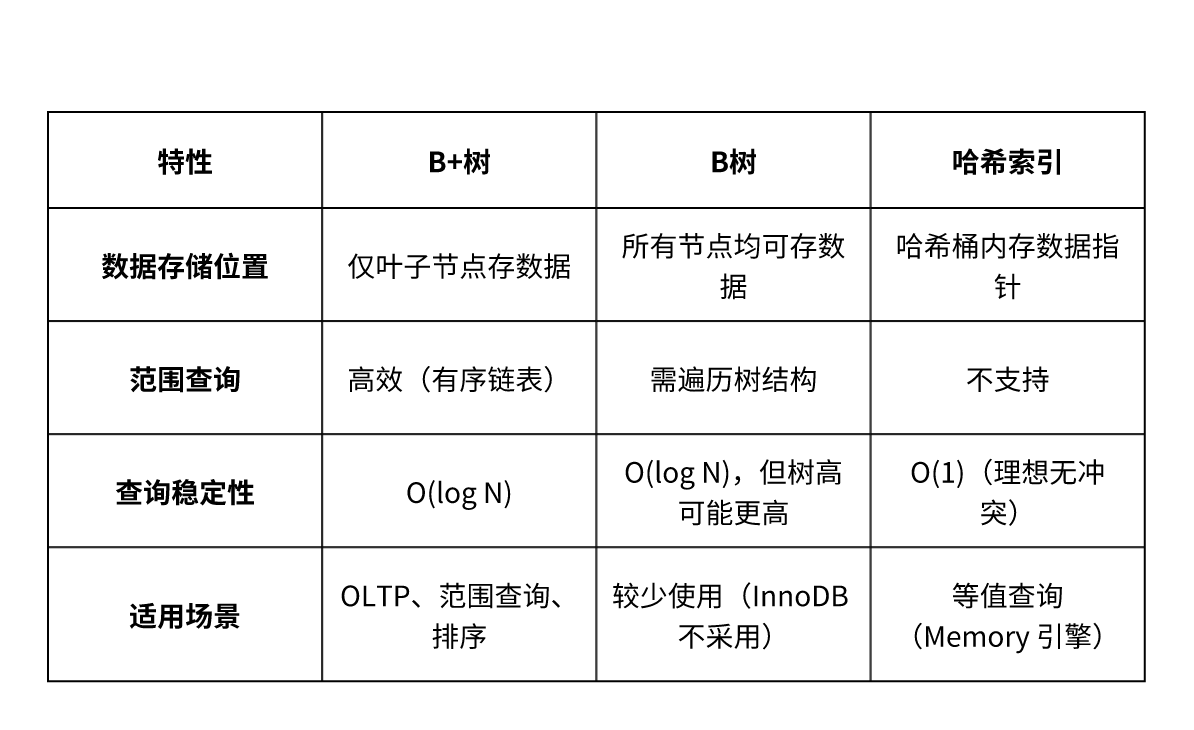
4. B+树 vs B树 vs 哈希索引
5. 联合索引(Composite Index)
- 多列组合索引:按定义顺序将多列值组合成索引键(如
(a, b, c))。 - 最左前缀原则:查询需命中索引的最左连续列,否则无法利用索引。 示例:
WHERE a=1 AND b=2→ 使用索引。WHERE b=2→ 不触发索引(未包含最左列a)。WHERE a=1 AND c=3→ 仅使用a列索引,c列不生效。
- 索引排序:联合索引默认按第一列排序,相同第一列时按第二列排序,依此类推。
6. 自适应哈希索引(Adaptive Hash Index)
- 自动优化机制:InnoDB 监控频繁访问的索引页,自动为热点数据创建哈希索引。
- 加速等值查询:哈希索引将等值查询时间复杂度优化至 O(1)。
- 局限性:
- 仅适用于等值查询(不适用于范围查询)。
- 哈希冲突由内部算法管理,用户不可见。
- 通过参数
innodb_adaptive_hash_index启用/禁用。
7. 索引优化建议
- 主键设计:
- 优先选择短且有序的字段(如自增整数),减少页分裂。
- 避免使用长字段(如 UUID 字符串)作为主键。
- 覆盖索引:
- 将频繁查询的字段加入索引,避免回表。
- 避免冗余索引:
- 删除重复或未被查询使用的索引(如
(a, b)和(a)可能冗余)。
- 删除重复或未被查询使用的索引(如
- 监控与分析:
- 使用
EXPLAIN分析查询执行计划。 - 监控
INFORMATION_SCHEMA.INNODB_INDEX_STATS查看索引使用情况。
- 使用
8. 示例:B+树查询流程
- 主键查询(聚集索引):
- 从根节点开始,逐层比较键值,定位到叶子节点,直接获取数据行。
- 辅助索引查询:
- 通过辅助索引找到主键值,再通过主键到聚集索引中获取数据。
过程图示:
辅助索引 B+树 → 主键值 → 聚集索引 B+树 → 数据行总结
InnoDB 的 B+树索引通过 高效的路由机制 和 有序数据存储,平衡了查询速度与数据维护成本。理解其结构有助于:
- 合理设计表结构和索引。
- 优化 SQL 查询性能。
- 避免因索引滥用导致的写入性能下降或存储浪费。