外观
MySQL 隔离级别以及存在的问题?
⭐ 题目日期:
腾讯 - 2024/08/19
📝 题解:
MySQL 支持四种事务隔离级别,每种级别在 并发控制 和 性能 之间进行权衡,不同级别下可能出现的并发问题如下:
1. 隔离级别概述
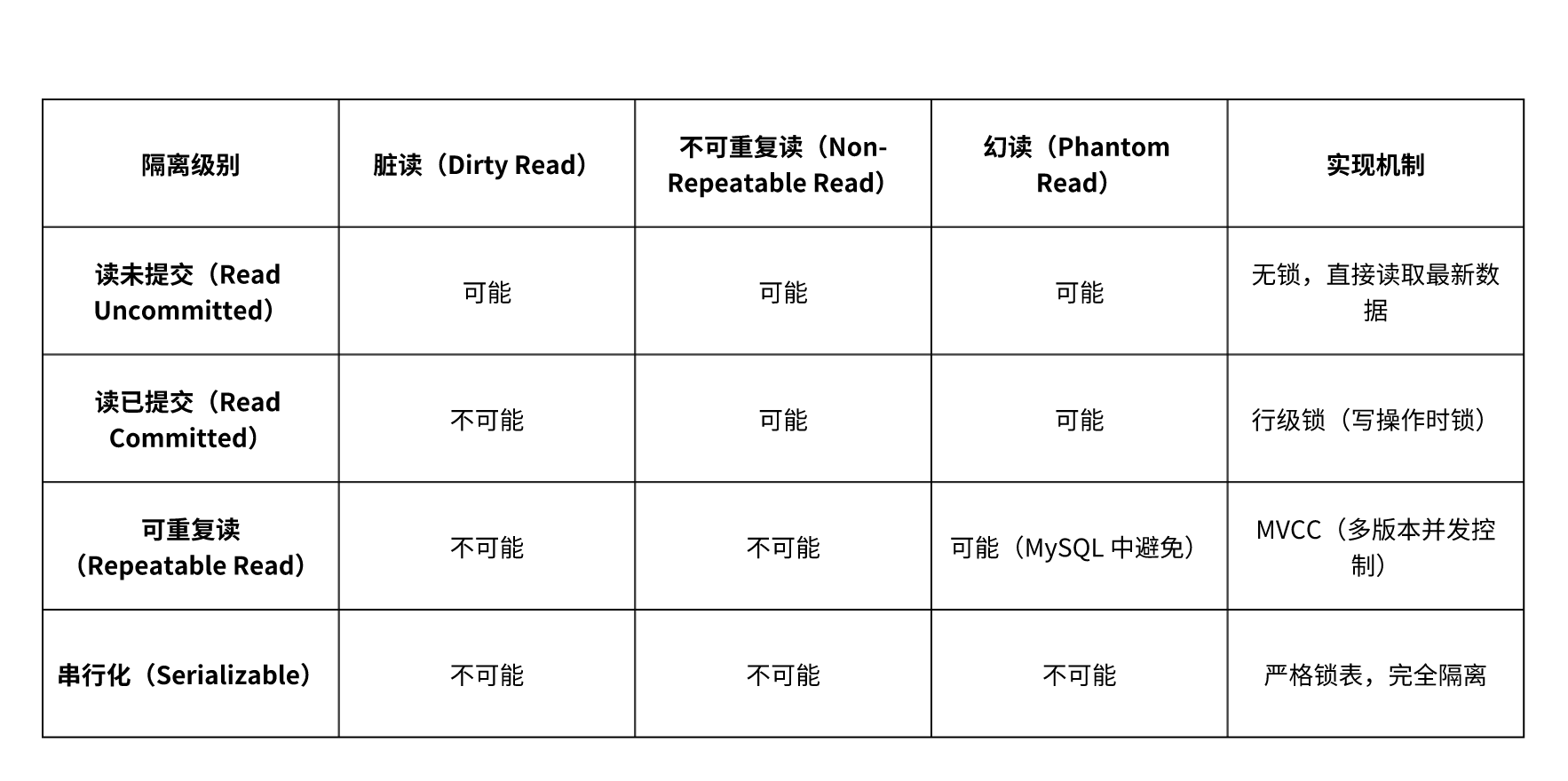
2. 各隔离级别存在的问题及解决方案
(1) 读未提交(Read Uncommitted)
- 问题:
- 脏读:事务 A 读取到事务 B 未提交的修改,若事务 B 回滚,事务 A 的数据不一致。
- 适用场景: 对数据一致性要求极低,仅用于统计分析等允许脏读的场景。
- 示例:
-- 事务 A
SELECT balance FROM account WHERE id = 1; -- 返回 100(事务 B 未提交的值)
-- 事务 B
UPDATE account SET balance = 200 WHERE id = 1; -- 未提交(2) 读已提交(Read Committed)
- 问题:
- 不可重复读:事务 A 多次读取同一数据,事务 B 在此期间提交修改,导致事务 A 前后结果不一致。
- 解决方案:
- 使用 行级锁(写操作时加锁,阻止其他事务修改)。
- 适用场景: 多数 OLTP 系统的默认级别(如 Oracle),允许一定程度的不可重复读。
- 示例:
-- 事务 A(第一次读取)
SELECT balance FROM account WHERE id = 1; -- 返回 100
-- 事务 B
UPDATE account SET balance = 200 WHERE id = 1; -- 提交
-- 事务 A(第二次读取)
SELECT balance FROM account WHERE id = 1; -- 返回 200(不可重复读)(3) 可重复读(Repeatable Read)
- 问题:
- 幻读:事务 A 按条件查询得到初始结果,事务 B 插入或删除符合条件的数据并提交,事务 A 再次查询出现新行或缺失行。
- MySQL 的优化:通过 Next-Key Lock(间隙锁 + 行锁)避免幻读。
- 解决方案:
- MVCC(多版本快照) + 间隙锁(锁定条件范围内的潜在插入位置)。
- 适用场景: MySQL InnoDB 的默认级别,适用于需要事务内数据一致的场景。
- 示例:
-- 事务 A(第一次查询)
SELECT * FROM account WHERE balance > 100; -- 返回空集
-- 事务 B
INSERT INTO account (id, balance) VALUES (2, 200); -- 提交
-- 事务 A(第二次查询)
SELECT * FROM account WHERE balance > 100; -- 返回新插入的行(幻读,但在 MySQL 中通过锁避免)(4) 串行化(Serializable)
- 问题:
- 性能低下:完全隔离通过锁表实现,并发性能最差。
- 适用场景: 对数据一致性要求极高的金融交易等场景,牺牲性能换取安全。
- 示例:
-- 事务 A
SELECT * FROM account WHERE balance > 100 FOR UPDATE; -- 加锁阻止其他事务操作
-- 事务 B 的插入操作将被阻塞,直到事务 A 提交3. MySQL 如何解决幻读?
- Next-Key Lock 机制: InnoDB 在可重复读级别下,通过 行锁(Record Lock) + 间隙锁(Gap Lock) 锁定索引范围,阻止其他事务在范围内插入数据。
- 示例: 若事务 A 执行
SELECT * FROM account WHERE id > 100,InnoDB 会锁定id > 100的所有现有和潜在插入位置,事务 B 插入id = 101的行将被阻塞。
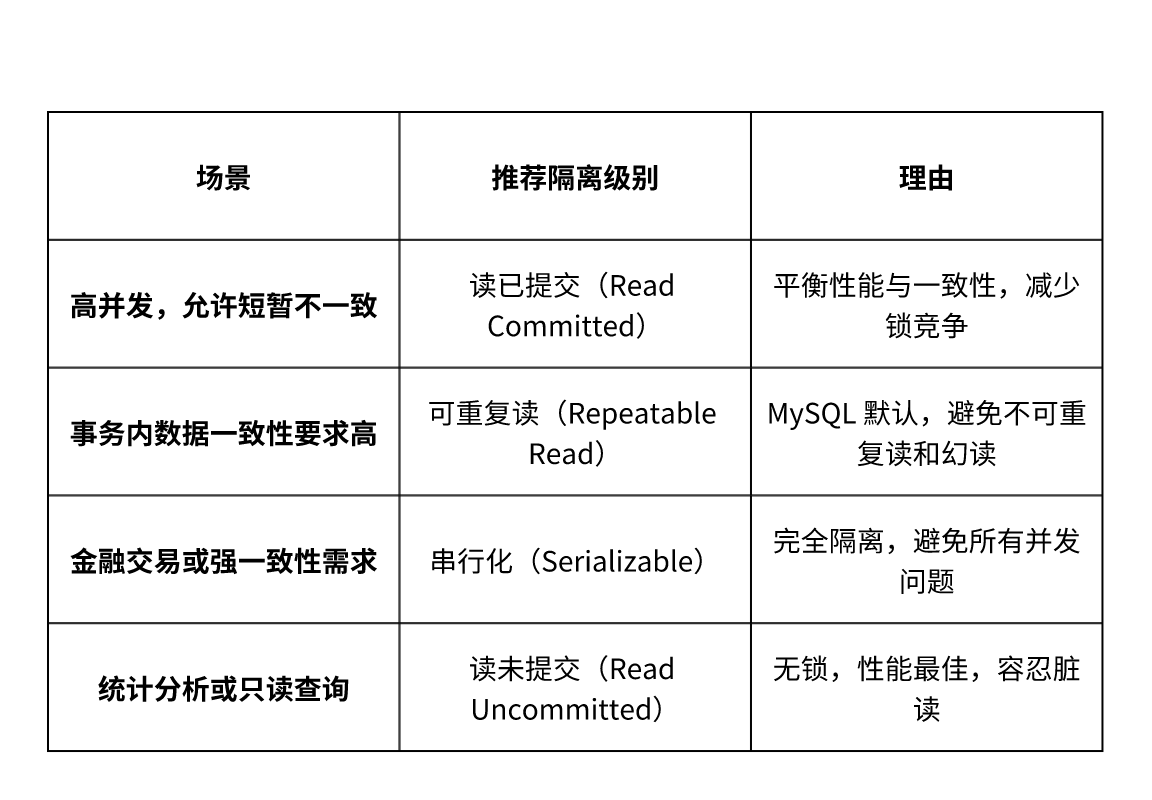
4. 隔离级别选择建议
5. 总结
- 读未提交:性能高,但存在脏读、不可重复读、幻读。
- 读已提交:解决脏读,允许不可重复读和幻读。
- 可重复读:解决脏读和不可重复读,通过 Next-Key Lock 避免幻读(MySQL 特有优化)。
- 串行化:解决所有问题,但性能最差。
根据业务需求选择合适的隔离级别,InnoDB 默认的 可重复读 在多数场景下兼顾性能与一致性。