外观
二级索引存放的是什么数据
⭐ 题目日期:
字节 - 2024/09/03
📝 题解:
在数据库中,二级索引(Secondary Index)的存储内容与主键索引(聚集索引)不同,其核心设计目的是 加速非主键列的查询,同时通过 回表(Bookmark Lookup) 获取完整数据。以下是二级索引的存储内容、结构设计及其作用:
一、二级索引的存储内容
- 索引列的值
- 存储定义索引时指定的列值(单列或联合索引的所有列值)。
- 示例:对
(name, age)列创建联合索引 → 叶子节点存储name和age的值。
- 主键值(Primary Key)**
- 二级索引的叶子节点会关联对应的 主键值**,用于回表查询完整数据行。
- 示例:若主键是
id,则二级索引叶子节点存储(name, age, id)。
二、二级索引的结构
1. B+树****结构
- 非****叶子节点:存储索引列的键值范围 + 子节点指针(路由导航)。
- 叶子节点:存储 索引列的值 + 主键****值,按索引列顺序排列,形成有序链表。
2. 示例:用户表的二级索引
假设表结构为:
CREATE TABLE user (
id INT PRIMARY KEY, -- 主键
name VARCHAR(100), -- 二级索引列
age INT, -- 二级索引列
address VARCHAR(200)
);- 二级索引定义:
CREATE INDEX idx_name_age ON user(name, age); - 索引存储内容:
叶子节点示例:
("Alice", 25, 1001) → 指向主键 id=1001 的行
("Bob", 30, 1002) → 指向主键 id=1002 的行三、二级索引的查询流程(回表)
- 通过二级索引定位****主键:
- 根据
WHERE name='Alice' AND age=25在idx_name_age索引树中找到对应的主键id=1001。
- 根据
- 通过主键获取完整数据:
- 使用
id=1001到主键索引(聚集索引)中查找address等其他字段的值。
- 使用
四、二级索引的特殊场景
1. 覆盖索引(Covering Index)**
- 定义:查询的字段全部包含在二级索引中,无需回表。
- 示例:
SELECT name, age FROM user WHERE name='Alice' AND age=25;2. 联合索引****的最左前缀原则
- 规则:查询必须命中索引的最左连续列,否则索引失效。
- 示例:
WHERE name='Alice'→ 使用索引。WHERE age=25→ 不触发索引(未包含name列)。WHERE name='Alice' AND address='...'→ 仅name列生效,address不触发索引。
五、二级索引的优缺点

六、二级索引的存储优化
- 前缀索引(Prefix Index)
- 对长字段(如
VARCHAR(255))仅索引前 N 个字符,节省空间。 - 示例:
CREATE INDEX idx_name ON user(name(10));→ 仅索引name的前 10 字符。
- 对长字段(如
- 压缩索引
- 对重复值较多的列(如性别、状态)启用索引压缩,减少存储占用。
- InnoDB 支持
KEY_BLOCK_SIZE参数调整索引页压缩率。
- 索引选择性(Selectivity)
- 高选择性(唯一值多)的列更适合建索引(如
user_id),低选择性列(如性别)效果差。
- 高选择性(唯一值多)的列更适合建索引(如
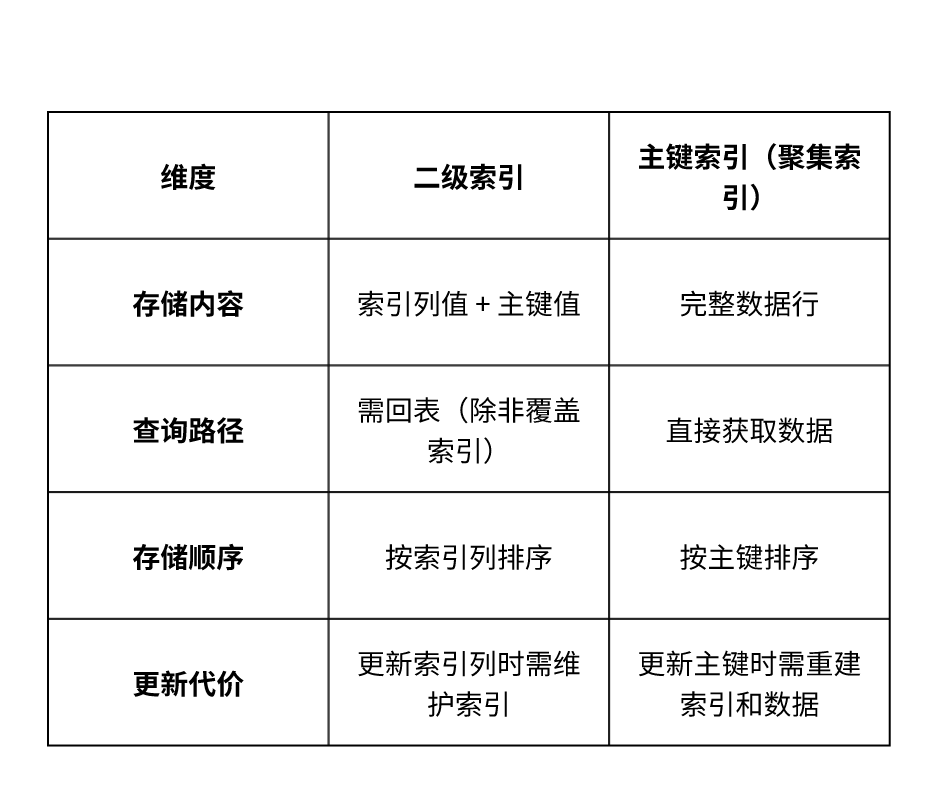
七、二级索引 vs 主键索引
总结
二级索引的核心作用是 加速非主键列的查询,其叶子节点存储 索引列值 + 主键值,通过回表机制关联完整数据。合理设计二级索引(如覆盖索引、联合索引)可显著提升查询性能,但需权衡存储开销和写入效率。